
中金解读“AI+数字孪生”:视觉筑基 三维重建+动捕技术为翼
AI是构建元宇宙的关键底层技术,本文从数字孪生的角度出发,阐述AI如何赋能物理世界和数字世界的连接,将物理世界的“人、物、场”映射到数字世界,实现实时映射、动态交互。我们将映射过程分为宏观和微观两层次,其中物、场等三维环境为宏观层面,基于三维重建技术实现映射;人的动作细节为微观层面,借助动捕技术完成映射。跨过2012深度学习元年,计算机视觉高速发展也驱动了基于视觉的三维重建和动捕路线的成熟,我们预计基于视觉的AI有望降低数字孪生生态的门槛,提速虚实相生进程。
摘要
底层技术:计算机视觉的进步为元宇宙的数字孪生应用打下坚实基础。计算机视觉作为数字孪生的重要技术基础,在经历了深度学习和Transformer大模型的两轮潮流后智能程度和可用性大大增强,被广泛应用在各种领域。大模型以较高的智能程度和较低的边际生产成本成为主流趋势,也强化了基于视觉的三维重建和动作捕捉技术,使得数字孪生趋于成熟。
实现路径:深度学习与传统路线实现互补,分别从宏观和微观连接物理世界和数字世界:1)三维重建领域,CNN(卷积神经网络)能从数据标注和修复、算法的优化等多方面对模型质量进行优化,解决传统方法精度和算力不足的问题,商汤等科技企业正在基于AI的三维重建领域探索商业化应用;2)动作捕捉领域,传统动作捕捉方法在电影、游戏制作等工业级场景下较为成熟,但存在成本高、环境要求严苛等问题。AI+光学式动捕近年来逐渐成熟,目前英特尔、商汤等科技企业已在该领域积极探索低成本的AI动捕;国内厂商在该领域百花争鸣,推动着AI+光学式动捕进入新的阶段,我们认为,未来国内厂商在该领域的技术和应用落地方面有望和国际厂商对标。
未来展望:我们认为计算机视觉未来有望实现更高程度的自动化、高精度和低功耗,进一步丰富元宇宙的内容生态,降低进入门槛。计算机视觉的进步引领了三维重建和动捕技术快速成熟,并逐渐在各自的领域积累技术进步。我们认为计算机视觉未来有望迎来进一步发展:1)更高程度的自动化,如AI自动合成仿真数据以解决长尾场景问题;2)更高的精度,如AI的智能图像降噪;3)更低的功耗,逐渐在移动端实现更好的视觉效果,被应用在大量下游行业,逐渐迈向连接物理世界和数字世界的长期愿景。
风险
AI技术进步不及预期;动作捕捉、三维重建等落地应用进度不及预期。
正文
概述:AI助力物理和数字世界的映射与交互,视觉为基
实现从物理世界到数字世界的映射和连接是元宇宙的重要环节之一。在《元宇宙系列研究:元宇宙系列之AI+数字原生:AIGC涌内容生成之浪,NLP筑智能交互之基》中,我们围绕AI赋能数字世界,以数字原生为中心,本篇则从数字孪生的角度出发,分析AI在物理世界到数字世界的映射中起到的作用。本篇报告分为技术基础、宏观、微观和未来展望四个部分,希望从宏观和微观两个部分,分析AI如何助力将物理世界的人、物、场映射到数字世界,其中“物”和“场”即三维环境属于宏观层面,“人”的细节属于微观层面。
图表:AI赋能元宇宙报告框架比较,本篇立足数字孪生(三维重建+动作捕捉)

资料来源:Google官网,OpenAI官网,浪潮信息,天智融合,臻图信息,虚拟主播公司“彩虹社”,Babylon.js,Vfxexpress online media,Digital Spy,中金公司研究部
技术底层基础:计算机视觉(CV)为元宇宙的数字孪生的底层支撑
高真实度的三维视觉内容与实时的交互是元宇宙沉浸感的重要来源。根据著名心理学家赤瑞特拉的大量实验,人类获取的外界信息约80%来源于视觉。我们认为,视觉领域是实现元宇宙的真实感和沉浸感的关键,元宇宙需要将物理世界的动作以视觉内容的形式复现到数字世界中,进而实现实时的交互。
计算机视觉连接了真实世界与数字世界,AI辅助的数字孪生或将是重要路线。元宇宙需要超大规模的三维视觉内容生产,目前视频领域的PGC、UGC模式效率较低,而全自动建模和渲染生产的内容暂时存在真实度瓶颈,难以直接应用到游戏、电影中。借助AI完成三维重建和动作捕捉等技术,复刻现实世界的环境和动作,我们认为或将是未来的重要路线。
深度学习引领计算机视觉高速发展,Transformer为CV注入通用智能
深度学习是人工智能的里程碑,卷积神经网络(CNN)是计算机视觉(CV)的主流技术。计算机视觉起源于上世纪六十年代,主要被应用于图像分类、对象检测、目标跟踪、语义分割和实例分割任务。但依赖“手工特征”+“机器学习分类”来完成识别、检测等任务的计算机视觉方法,其准确率一直难以提升到商用的标准,因此在业界沉寂了很长一段时间。2012年深度学习兴起后,其效果远强于以往的计算机视觉模型,从此卷积神经网络(CNN)成为各类计算机视觉任务的主导模型。
Transformer大模型2017年由谷歌在NLP领域提出,后来跨界进入CV领域,树立新的里程碑。2017年谷歌提出Transformer模型,其并行化的语言处理方式使得并行计算效率大幅提升,解决了CNN只能依据词语顺序处理的问题,并在此后推出GPT-3(第三代Transformer模型)这样的大参数量模型,利用大数据集提升了模型的智能程度。2020年谷歌提出视觉Transformer模型(ViT),其在ImageNet-1K评测集上取得了88.55%的准确率并刷新榜单纪录,学界才逐渐意识到Transformer不仅适用于NLP领域,也有望在CV领域发挥作用。
图表:计算机视觉技术发展历史
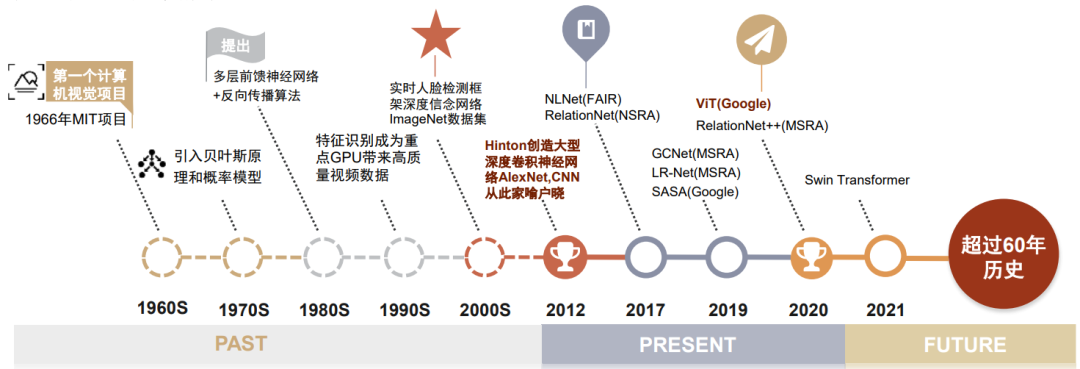
资料来源:AI科技评论,京东科技,微软亚洲研究院,中金公司研究部
技术细分领域:三维重建和动作捕捉分别提供宏微观的虚实连接
数字孪生兴起于工业领域,指以3D数字化的方式将物理世界引入数字世界。目前,数字孪生这一概念主要指通过数字化、知识机理等技术构建数字模型,利用物联网等技术从真实物理世界转换而来的通用数据,依托AR/VR/MR/GIS等技术将物理实体复现在数字世界中。凭借创建的虚拟实体中的历史数据、实时数据和算法模型等,通过人工智能、云计算、大数据等技术加持,对物理实体进行模拟、验证、预测、控制全生命周期过程的智能决策,最终赋能于各垂直行业。
数字孪生是数字化的高阶阶段,人工智能是数字孪生生态的底层关键技术。我们认为,随着人工智能、大数据、物联网等技术加速赋能传统建模仿真技术,在可以想象的未来,数字孪生将在虚拟世界创建与真实物理世界实时联动的资源优化配置体系,在制造、建筑、医疗、城市管理等各个领域发挥重要作用。人工智能是发展数字孪生的底层关键技术之一,主要贡献在于海量数据的处理以及系统的自我迭代优化两方面,保证整个数字孪生系统有序运行。
图表:数字孪生应用于跨江大桥建设
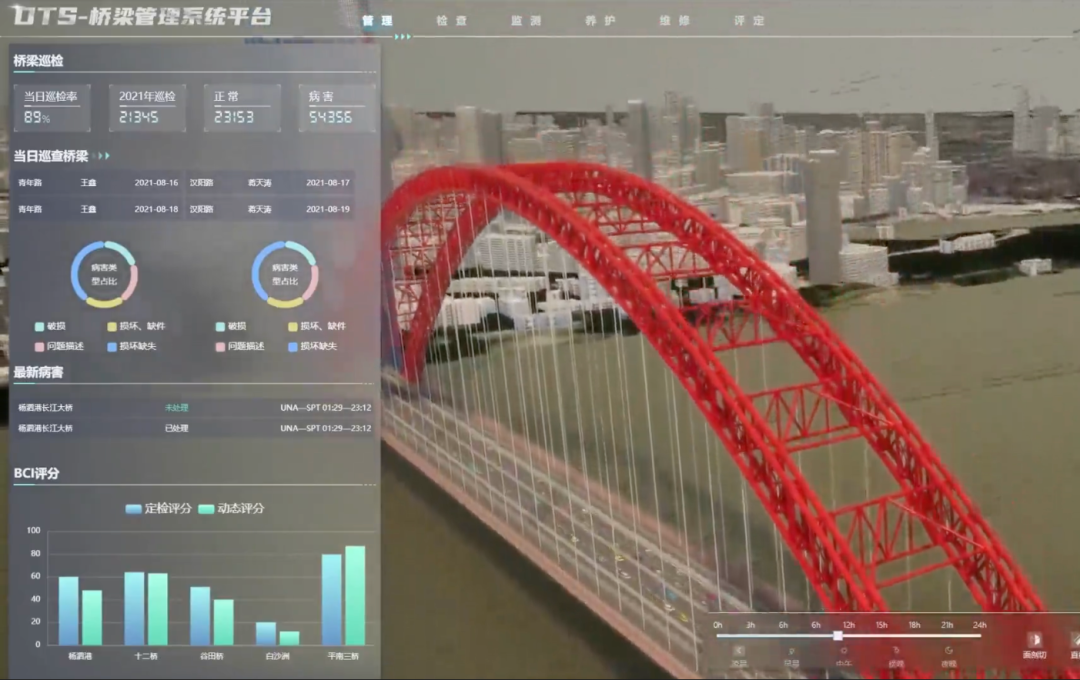
资料来源:数据工匠俱乐部,中金公司研究部
图表:数字孪生应用于自动驾驶测试

资料来源:清华大学苏州汽车研究院,中金公司研究部
在数字孪生的过程中,三维建模与动作捕捉技术分别从宏观和微观两个角度建立连接物理与数字世界的基础。宏观层面,建模能将物理世界环境、系统等的形状、位置、接口、数据、状态等搭建为可以运行的模型,动捕则能在微观层面将人类或动物的实际运动转化为计算机可识别分析的数据形式并进一步体现在虚拟世界中。动捕和建模分别将真实世界中的微观与宏观投射到虚拟世界当中,是基于现实世界构建元宇宙的技术基础。
三维重建:从宏观上重构物理世界的三维空间
技术基础:三维重建是实现宏观层面数字孪生的重要手段,AI引领技术突破桎梏
三维重建是数字孪生的虚实结合关键技术,是将物理世界宏观部分中“场”和“物”的对象映射到元宇宙实现数字孪生的过程。数字孪生中的建模指的是利用多学科知识,将真实世界中的目标物体表达为计算机所能识别的数字化模型,可以理解为对真实物理世界的问题进行简化和模型化。数字孪生建模可以实现对目标对象全方面特征的刻画,从而能够在虚拟世界中模拟物理世界中的行为,对未来发展趋势进行预测和分析。
传统三维重建路线成熟,人工智能带来互补优势
三维重建经过数十年的发展, 传统方法已经具备成熟路线。基于视觉的三维重建主要指在利用仪器获得目标物体二维图像数据后,通过一系列分析处理,根据相关理论重建出真实物理世界的物体信息。3D建模具有高速、实时性等特点,在机器人、VR、3D打印、SLAM (Simultaneous localization and mapping)等领域广泛应用。其分类方法如下图所示:
图表:三维重建传统技术路径一览
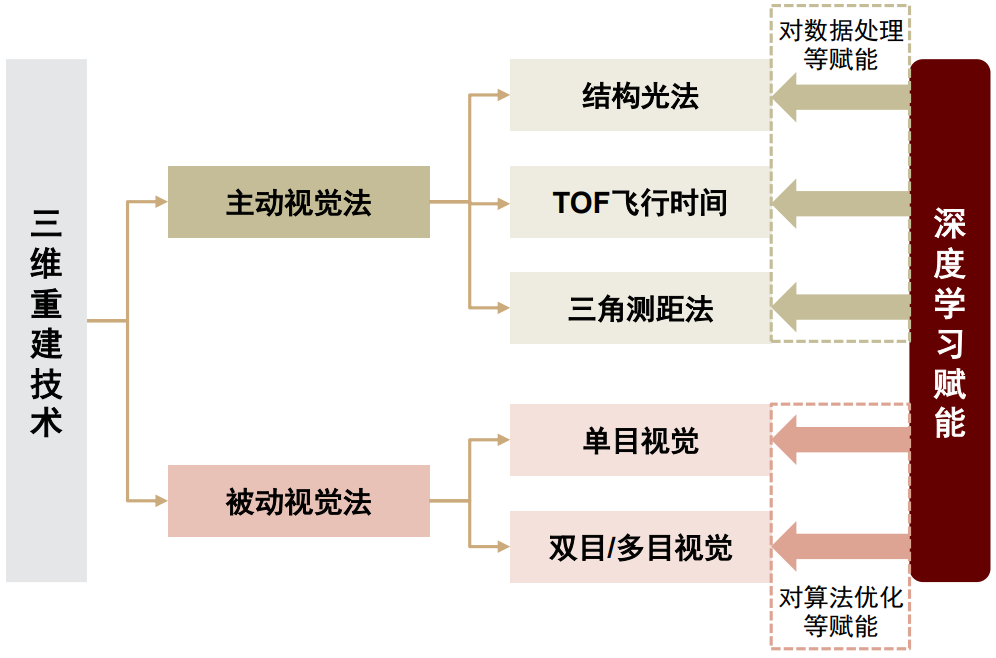
资料来源:《基于视觉的三维重建关键技术研究综述》(郑太雄等,2020),中金公司研究部
传统3D建模的主流路线包括主动式的结构光法、TOF技术、雷达技术等和被动式的单目/双目/多目视觉法、区域/特征视觉法、机器学习法等。传统3D建模主要分为基于主动视觉和基于被动视觉两种路线:1)基于主动视觉的3D建模技术主要是通过传感器向物体照射不同种类的信号,并根据返回信号解析获得物体信息;2)基于被动视觉的3D建模技术主要是直接依靠周围光源,根据多视图几何原理进行逆向工程建模,从而获得目标物体的三维信息。
图表:传统主动与被动视觉法各有优劣势与适用场景
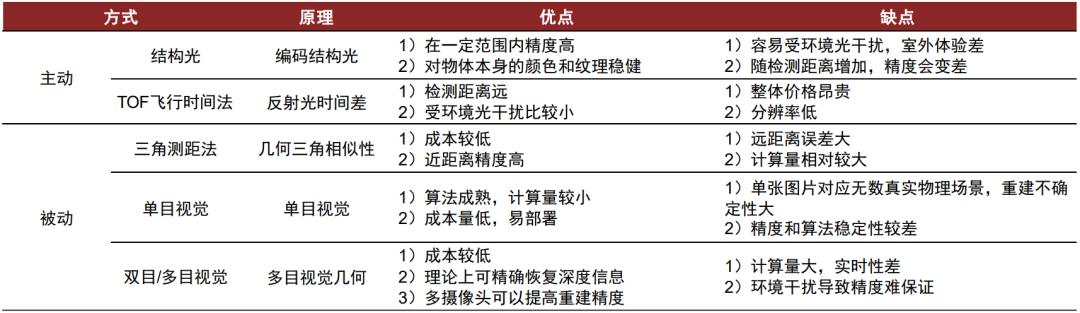
资料来源:3D视觉工坊,中金公司研究部
基于计算机视觉的3D建模与传统方法能够优势互补,并在使用深度学习算法改良后取得显著突破。CNN运用于图像特征匹配具备能够适用于高维图像数据、高效提取特征、大幅减少参数等优势,因此这一领域涌现出了诸多研究。
图表:深度学习应用于定位与建图的模型示例
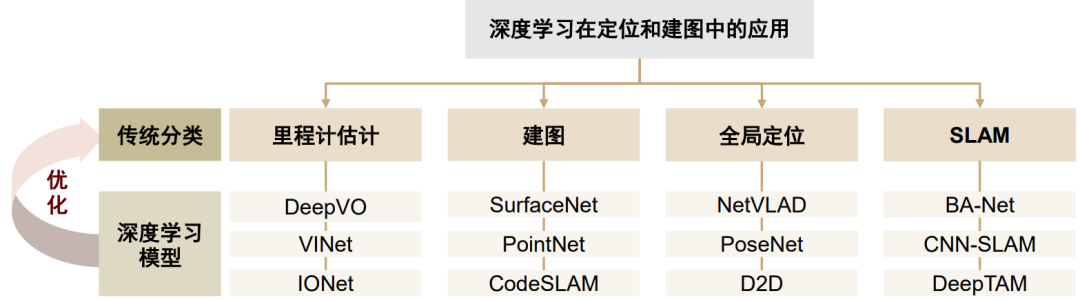
资料来源:A Survey on Deep Learning for Localization and Mapping: Towards the Age of Spatial Machine Intelligence,C Chen,B Wang,CX Lu,N Trigoni,A Markham,2020,中金公司研究部
相比多视图几何建模,基于视觉的深度学习路线能够实现更高的上限。从原理上来说,与计算机几何建模不同,深度学习使用类似人类基于大脑的3D建模方式,基于各类信息直接进行三维重建。基于深度学习算法的三维重建的数据格式目前主要分为三种:1)体素(voxel),与2D中像素相对应的3D体积像素概念;2)点云(point cloud),由含有三维坐标、色彩、反射强度信息的点构成;3)网格(mesh),一种便于计算的多边形网格。
图表:深度学习三维重建的三类输入信息示意图
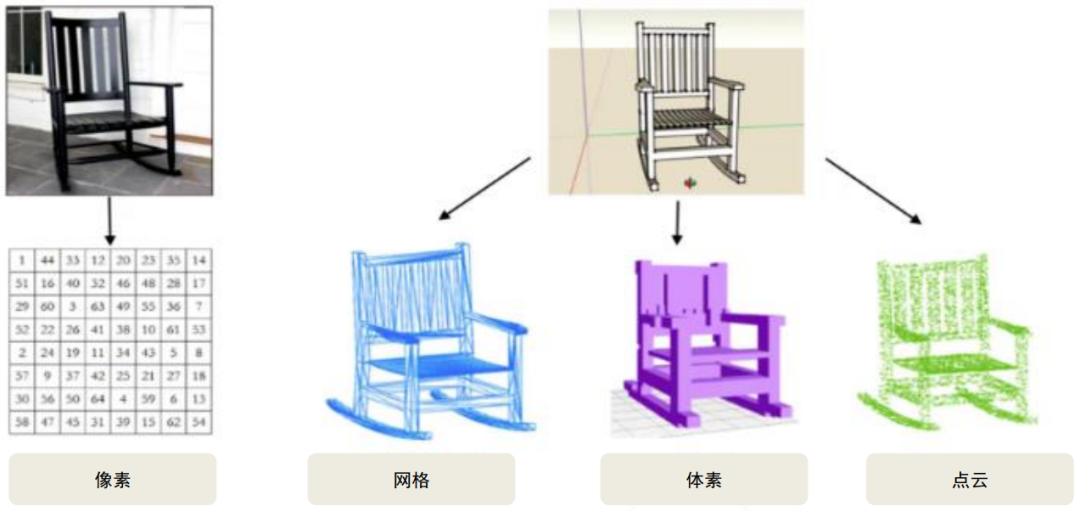
资料来源:CVPR,中金公司研究部
人工智能为三维重建行业的各个环节均带来了优化提升,包括预处理、重建和数据应用。1)预处理环节,传统三维重建受原始数据色彩、明暗不均匀的因素影响导致色彩差异大、纹理模糊,AI可以自动修复原始数据,提升三维模型质量;2)传统三维建模由于对各种实体元素用同一种方式处理,会导致“鬼影”、水面缺失等问题,AI可以对水面、路标等重建难度大的元素智能识别并采用针对性的算法重建,以实现重建模型质量提升;3)人工智能能自动监测变化的场景区域,并对变化趋势进行分析,将场景要素的变化融入进去。
应用实例:头部软件厂商布局,国内处落地初期,聚焦建筑和医疗
AI解决稳定性与实时性问题,龙头纷纷布局
AI有望解决三维重建的应用过程中的稳定性和实时性问题。实际进行三维重建的相关应用如SLAM实时定位、AR导航的过程中,常常面临两大问题,一是稳定性,二是实时性。SLAM定位能够在纹理信息丰富的区域稳定工作,但是部分区域没有足够的纹理信息,或者存在相似的重复纹理,以及光线等外界条件也会干扰采集到的纹理信息,这会干扰系统的稳定性。此外,在低功耗的移动设备上实时计算、匹配城市级场景等大规模数据的难度也很高。
图表:视觉SLAM的关键挑战以及对应解决思路
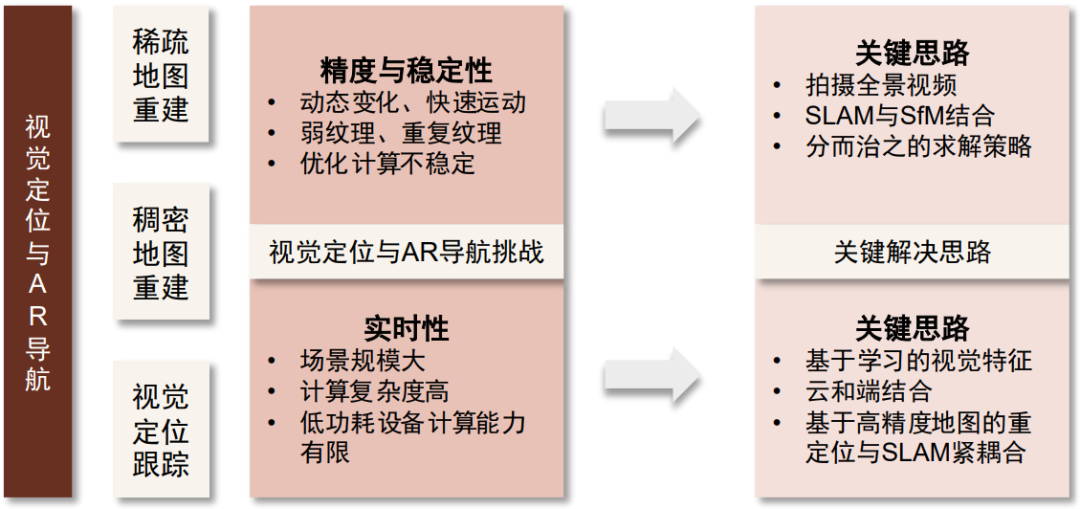
资料来源:商汤科技公众号,中金公司研究部
AI结合5G、边缘计算等技术有望解决SLAM实时定位的精度和稳定性问题。以商汤科技研发的SenseSLAM为例,计算方式上结合云、边、端,通过各类传感器(各类摄像机、GPS数据、惯性测量单元等)融合的数据预先完成场景的三维重建,结合云、边算力进行光照估计、真实感渲染、遮挡处理等进一步大尺度虚实融合处理,最后将处理好的高精度地图储存在云端。在实际使用时,再向终端传输高精度地图数据以优化终端的SLAM结果,从而实现低功耗设备在大空间内高精度定位。
图表:AI结合5G、边缘计算解决SLAM实时定位的精度和稳定性问题

资料来源:商汤科技公众号,中金公司研究部
商汤科技自主研发的SenseMARS火星混合现实平台,能基于低成本的AI视觉,实现室内外精准定位和AR导航。商汤科技SenseMARS能够实现室内、室外等多种场景的AR特效、导航、导览等功能,支持高精度的数字化地图3D重构,可以在安卓、iOS、Web、小程序等多种系统和手机、平板电脑、XR设备等多种设备上实现三维空间定位。SenseMARS由商汤视觉实验室和浙江大学联合研发,其地图数据来源于各类传感器,可以基于单节点服务器,在一小时内采集约2万平方米的场景数据,并实现厘米级精度的三维重建,同时正确处理遮挡、碰撞等人机交互场景。
结合AI对位置、轨迹、交通、地块等数据进行智能分析,腾讯WeMap三维重建引擎融合各类信息,并生成高精度的三维地图,并广泛应用于城市、交通、商业、环境等业务场景。过去三维数据采集和处理常常遇到分块接边处理困难、重建速度慢、各类数据融合过程繁杂等问题。腾讯WeMap能够高效重建大规模数据,其通过智能纹理算法避免光照带来的阴影混乱,使得三维地图的色彩过渡更加均匀。结合腾讯过去在地图领域的案例积累,WeMap能够构建实时的三维地图数据,并在此基础上提供各类应用和服务。腾讯WeMap由五大产品构成,包括数据工厂、数据管理平台、智能分析平台、可视化平台、产业地图服务平台,其中数据工厂和数据管理平台是底座,三大服务平台为客户提供各种应用服务,包括空间分析、时间模拟、融合位置服务、路况调度等。
图表:腾讯WeMap与三维重建能力
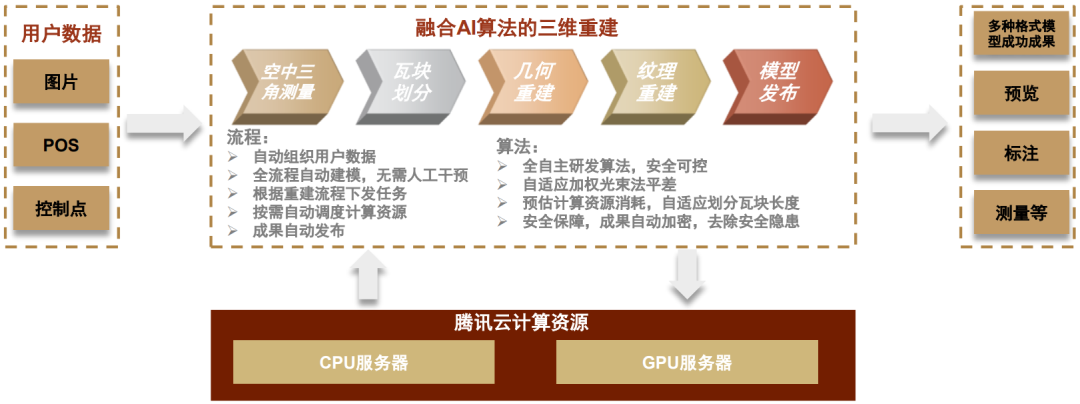
资料来源:全球地理信息开发者大会,中金公司研究部
三维重建市场广阔,海外大型软件公司纷纷切入
三维重建行业暂时未进入技术突破带来的需求爆发阶段,市场规模较小、增速较慢。根据知名咨询机构Market Research Future(MRFR)的估算,2022年全球三维重建行业市场规模约为8.4亿美元,预计2021-2028年CAGR为14.1%,预计2028年达到约18.6亿美元,市场增长的主要驱动力来源于建筑、医疗保健行业对于三维重建技术的需求增加,此外,三维重建技术也被应用于汽车、国防、工业、娱乐等领域。三维重建技术的主导区域为北美和欧洲,但中国也出现了四维时代、众趣科技、如视、旭东数字、EDDA健康科技等头部企业。
图表:三维重建行业的行业分类、头部企业、市场规模概况
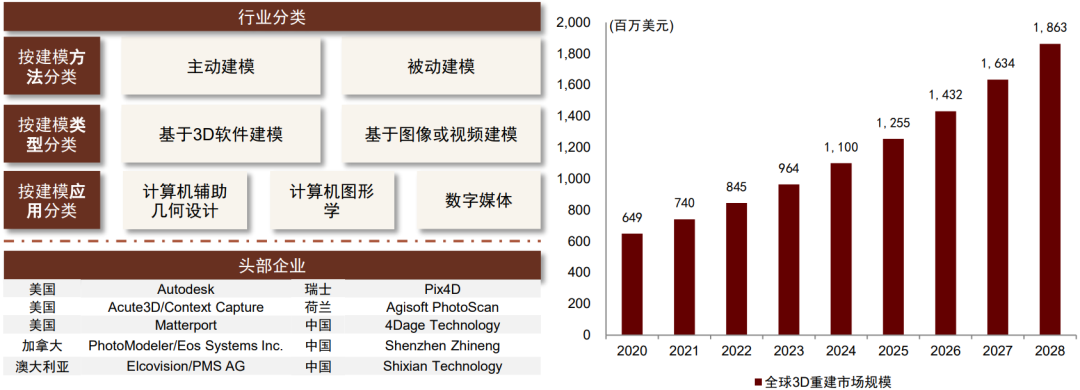
资料来源:Market Research Future,中金公司研究
海外数字原生领域龙头企业逐渐切入三维重建行业以丰富产品线:1)Autodesk:如创立于1982年的Autodesk从CAD软件起家,产品主要下游应用领域包括建筑、制造、媒体、教育和娱乐行业,此后切入三维重建领域;2)Bentley:其拥有4,500余名员工,服务于186个国家/地区,年收入逾10亿美元。Bentley旗下的ContextCapture软件将三维重建技术应用于设计、施工领域,主要分为ContextCapture、ContextCapture中心、ContextCapture云服务三种销售方式进行销售,采用点云的形式进行三维重建,直接基于图像生成三维模型,提升设计、施工、运营等领域效果。
由于局限于工业级的应用,也没有类似AI、区块链领域高速增长的市场需求,三维重建的一级企业的融资呈现轮次多、金额小的特点,但这也倒逼了公司的商业化能力。以Matterport为例,其从2011年创立之初到2022年8月共经历了13轮融资,共从一级市场融资4.09亿美元,根据其最新公布的2021年财报,其2021财年实现了年化经常性收入(ARR)6,610万美元,总客户达到约50万个,同比2020增长98%,公司预计其2022年年化经常性收入有望达到约8,100万美元总收入约1.3亿美元。而根据Crunchbase,脱胎于瑞士洛桑联邦理工学院的PIX4D公司只进行过五轮融资,融资总金额仅为260万美元。PIX4D在2011年成立后长期专注于三维重建,产品被广泛应用于测绘、农业、建筑、教育、电信等领域。
国内三维重建企业处于发展初期,主要从建筑和医疗领域切入
同海外类似,国内三维重建领域的初创企业也存在融资较为温和、变现能力较强的特点。国内三维重建企业主要从房产建筑、医疗两大领域切入进行商业化,主要由于建筑行业客户规模大、付费能力强,众趣科技、亦我信息等企业也分别获得了广联达、我爱我家等房地产建筑领域的产业投资加持。与海外公司类似,由于市场规模相对小、需求增速较为平缓,大多三维重建企业融资频率和融资金额相对商汤这类人工智能企业较低,如四维时代、亦我信息、非白三维等企业的融资金额都不超过一亿元人民币,但也倒逼了三维重建的初创企业的商业化能力。
图表:国内部分头部三维重建企业融资历史

资料来源:36氪,众趣科技官网,亿欧网,中金公司研究
四维时代(4DAGE)专注于三维重建领域,基于光学相机和人工智能算法,大幅降低了三维重建产品的成本。四维时代成立于2014年,在AI赋能的三维重建领域实力雄厚。公司的3D数字化重建技术中心的微米级三维数字化精细扫描技术较传统三维建模方式在效率上提高200倍以上。公司以四维看看Pro 3D空间相机、四维看见、四维深时三大产品为核心,打造了房产营销、线上展会、数字文博、VR购物、安防勘察五大产品解决方案。四维时代基于光学相机和人工智能算法研发了四维看看实景三维相机,可以直接把二维数据变成三维数据。该技术难点在于建模速度和精度,四维时代庞大的数据库加速建模过程,能克服建模过程中的障碍如反光物体、特征点少,一般设备根据120个点位的照片生成模型需12小时,且需要依赖专业人员,四维看看仅需要十分钟自动生成模型。
如视科技2017年诞生于贝壳,更擅长于局部空间三维建模,优势在于业务规模大、数据量大。如视科技四大核心产品涵盖了专业级、轻量级、消费级三大梯度,包括激光VR扫描仪伽罗华、智能手机云台REALSEE G1、全景相机采集、手机采集,提供空间数字化解决方案和场景营销解决方案。根据公司官网,如视科技200余个客户分布在27个国家和地区,数字空间采集量达到2,200万套,总面积达16.86亿平方米。公司大客户以房地产企业为主,包括贝壳、自如、立邦、日本丸红、阿根廷Obras-YA等,也包括文旅、零售领域的相关博物馆、美的电器等企业。
亦我科技(也叫“123看房”)专注于AI+三维重建,主要从房产建筑、大型展览等领域切入。亦我科技成立于2014年,公司主要将三维重建技术赋能到各行各业。根据公司官网,亦我科技是全球首个通过机器学习、深度学习等人工智能算法实现对大型空间3D建模并海量应用的技术领导者,目标为实现低成本的3D建模的技术提供者。目前公司已经为全球上百家中大型企业提供了3D建模的产品和解决方案,包括日本铁路、红星美凯龙、碧桂园、新城控股、金侨集团、58集团、安居客、房天下、我爱我家等众多政府单位及知名企业。
EDDA健康科技将三维重建应用于医疗领域,公司成立时间早、规模相对较大。EDDA健康科技成立于2004年,旗下包括医软信息、医达极星和EDDA Technology三家公司,总部分别位于上海、苏州和美国普林斯顿。公司业务广泛,以手术机器人为核心,产品包括智能化手术机器人、精准手术规划及模拟、术中导航、智能云平台等。EDDA发挥影像分析领域的核心技术优势研发IQQA®-3D系统,可以对患者胸腹部三维影像进行量化解读,可根据胸腹部的CT或MR影像在三维与胰腺、肝脏、肺脏等多个脏器进行实时交互、智能分析评估。
动作捕捉:从微观上映射人物的动作与表情
动作捕捉也是数字孪生的虚实结合的关键技术,是将物理世界人物细节的动作投射到元宇宙微观场景中“人”的过程。数字孪生中的动作捕捉指通过各种技术捕捉人或动物的动作细节,并将其转化为数字信息,以实现物理世界和数字世界的交互。动作捕捉过去常被用于电影、游戏领域,作为一种数字内容生产方式被广泛使用。未来在元宇宙中,我们认为动作捕捉将成为一种重要的交互方式,将物理世界中人的动作和表情实时映射到元宇宙当中,实现物理世界和数字世界的实时连接、动态交互。
技术基础:AI大模型削弱标注依赖,解决成本+精度双重痛点
传统动捕技术复盘:光学式动捕为主流,落地成熟但具技术瓶颈
动作捕捉技术自诞生起和计算机图像紧密相连,主要被用于各类电影和游戏中。我们将动作捕捉技术的发展历史大致划分为三个阶段:1)1980年之前,动画电影还主要停留在逐帧转描和定格动画技术,1937年的动画片《白雪公主》就出自转描技术,虚拟人物制作的效率低、成本高、质量低;2)1980-2000年之间,计算机视觉开始被引入电影特效制作,同时开始出现机械式动捕、光学式动捕等技术,但这个阶段的动作捕捉仍然存在动捕动画质量低、无法捕捉面部表情、无法进行室外动捕等缺陷,这段时间代表作包括1997年《泰坦尼克号》、1999年《星战前传1》等;3)2000年之后,动捕技术逐渐完善,探索出解决室外动捕、高质量动捕角色制作、面部表情的精准捕捉等难题的方案,2001年《指环王》、2009年《阿凡达》等作品是这一时期的代表作。
目前光学式动作捕捉-标记点式是主流技术。动作捕捉技术可分为光学式动捕-标记点式、光学式动捕-无标记点式、惯性式动捕、电磁式动捕、声学式动捕、机械式动捕。目前光学式动捕与惯性动捕是主流技术,光学动捕识别精度高、动捕效果好,但成本也较高,主要用于制作复杂的电影上,而惯性动捕则凭借低廉的成本、较少的后续处理程序更多被用于流媒体创作者等预算较少、对捕捉精度要求低的需求上。
深度学习助力动捕,降低标注需求,实现更高动捕精度
目前基于深度学习的开源软件包能够基本完成动物的动作捕捉。深度学习出现前,大部分上一代的动物动作追踪软件工具只能大致确认质心、方向,如果要捕捉更精细的细节则需要其他硬件或实验环境的配合。而目前DeepLabCut、LEAP Estimates Animal Pose和DeepFly3D等基于深度学习的开源软件包已经能直接根据视频信息,确定动物身体部位的坐标,从而完成动物的复杂动作捕捉。
图表:深度学习算法DeepLabCut可以实现较高的动作捕捉精度

资料来源:Github,中金公司研究部
动作捕捉的门槛的降低将导致数据的丰富度迅速提高,加速动作捕捉算法效果的提升。我们认为DeepLabCut、LEAP Estimates Animal Pose和DeepFly3D等AI开源软件包的出现能够使得动捕的数据丰富度快速提高,因为这些工具包仅需要少量的标注数据,就可以满足从猎豹运动到集体斑马鱼行为等各类动作捕捉场景的需求。这意味着我们可以将大量运动动作的视频转化成动捕数据,且存量的海量视频数据都可以用于这类基于计算机视觉的动捕算法的训练,而大量数据又会带来模型识别精度和质量的提升,最终有望开启标准AI模型的时代。不过目前大部分软件工具包仍有局限性,比如需要特定的实验设置或多目标追踪效果差。
应用实例:AI提升精度与质量,动捕落地方兴未艾
消费级产品:光学式动捕产品尚不成熟
目前市场上暂时没有出现门槛低、效果理想的消费级动捕产品。以消费级动捕产品领域较为成功的微软为例,微软2010年发布消费级动捕产品Kinect V1,与Xbox 360捆绑销售,早期的Kinect V1由于动捕技术不完善、内容生态不丰富退出市场。此后,微软在2019年重新发布Azure Kinect DK工具包,其集合了多款AI传感器,覆盖深度,视觉,声音和方向四大类别,包括100万像素TOF深度摄像头、1,200万像素高清摄像头、7麦克风圆形阵列和方向传感器,但其主要为开发人员提供服务。目前市场暂未出现成熟的消费级动捕产品,但是在入门场景如个人虚拟主播,开始出现便宜好用的消费级动捕产品。
图表:Kinect V1的动作捕捉示意图

资料来源:Zugara,中金公司研究部
工业级产品:积极探索基于人工智能的光学式动捕产品
英特尔3DAT系统在2022年北京冬奥会中大放异彩。以冬奥会速度滑冰的大场地为例,3DAT系统采集该场地范围内运动员动作仅需三个普通摄像头,即使是普通手机摄像头拍摄的训练视频也足以支持完成3DAT系统捕捉运动员的运动数据,且运动员无需佩戴任何传感器设备即可被捕捉到高度运动时的所有动作。
3DAT技术能迅速生成被采集者生物力学数据参数集,实时展现动捕效果,便于教练进行运动员评估、指导调整。依靠英特尔基于卷积神经网络的深度学习算法支持,使用通用的推理API,3DAT能从拍摄的训练视频中精确地提取人体关键骨骼点信息特征,实时三维重建运动轨迹、姿态,最终输出坐标点或者特征图,为每位运动员建立独立的数据库,从而为教练员评估运动员并制定调整训练计划提供科学参考,上述整体耗时总共仅需十几分钟,大大提高了教练员的指导效率。
图表:英特尔3DAT系统捕捉速度滑冰动作
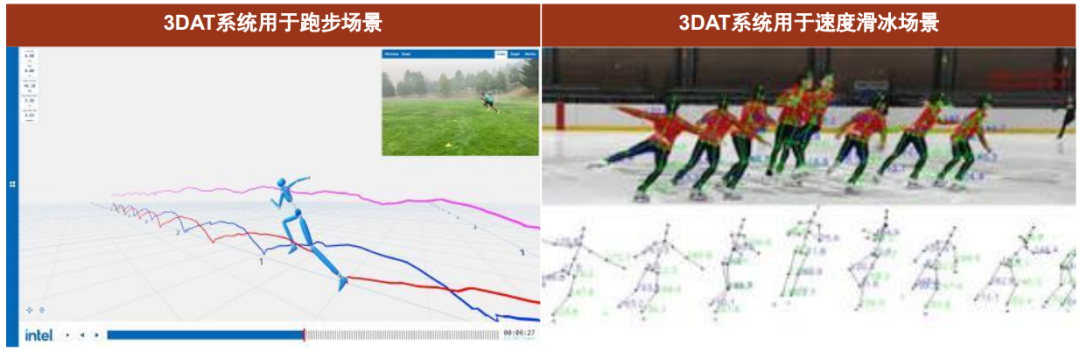
资料来源:英特尔官网,电子工程世界,中金公司研究部
3DAT系统未来有望逐渐渗透到其他动作捕捉领域及非专业领域。3DAT不仅可以用于速度滑冰场景,还包括花样滑冰、越野滑雪及其他场景的运动捕捉,只要拥有训练好的模型,就能通过OpenVINO部署。根据英特尔的相关专家介绍,每个场景只要采集5万张图像,就能完成对某一场景的动捕AI模型的训练和适配,并且算法还能基于具体需求做出调整。从更长期的视角看,我们认为类似于3DAT系统这样的基于深度学习的无标记光学动捕系统将逐渐应用在相关场景,包括游戏、AR/VR等领域。而一旦这样的消费类场景出现方便好用的动捕技术,将会催化该场景下内容生态的完善,从而带动对应场景AR内容的全面繁荣。
人工智能将引领光学式动捕技术持续进化
以深度学习为代表的AI技术降低动作捕捉门槛的同时,也在提高动作捕捉的质量。通过研究动作捕捉相关算法,我们发现深度学习一方面降低了动作捕捉的门槛,也逐渐提高了动作捕捉技术的捕捉效果。以机器学习算法PhysCap为例,其由马克斯普朗克研究所和Facebook现实实验室在2020年联合开发,其可以基于每秒25帧的普通单反相机进行人体动作捕捉,并且实现物理上合理、实时和无标记捕捉。
图表:PhysCap通过运动学重建实现了动捕数据的力学可信、环境交互可信

资料来源:马克斯普朗克研究所,Facebook现实实验室,中金公司研究部
以强化学习为代表的AI技术可通过设定目标让机器求解,使其在这一过程中自主生成和调整动作。采用动捕技术生成的动作虽然真实,但几乎完全固定,面对陌生任务或环境时难以自主调整。对此,DeepMind在2017年采用强化学习思路进行机器人的动作生成,过程中并未明确为机器人设定行动,而是对机器人下达目标指令,机器人在多次训练后即可通过强化学习的反馈机制自主生成行走、跑步、跳跃等动作。腾讯四足机器人Robotics X Max亦采用相似的思路进行动作训练,让机器人利用强化学习算法学习动捕数据,根据外界变化自主生成动作及行为,从而使机器人在面对陌生障碍物时,也能灵活调整路线来完成既定目标。
图表:DeepMind利用强化学习使机器自主生成动作
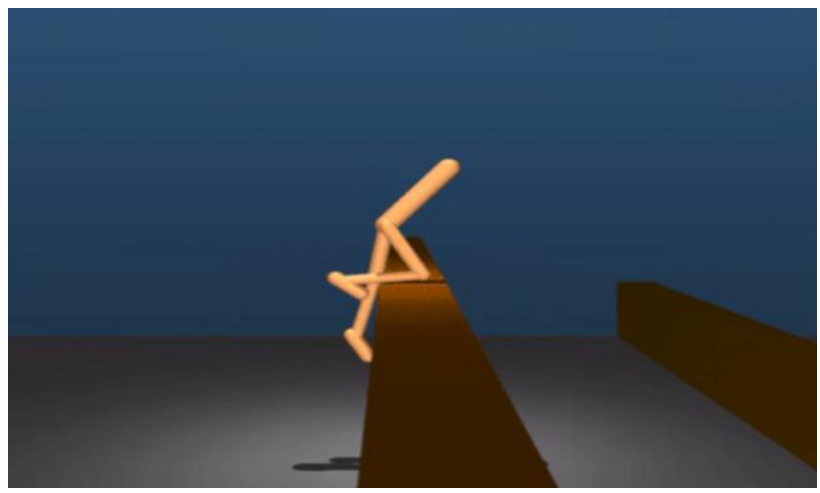
资料来源:DeepMind,中金公司研究部
图表:腾讯采用智能体动作生成技术训练机器人Robotics X Max
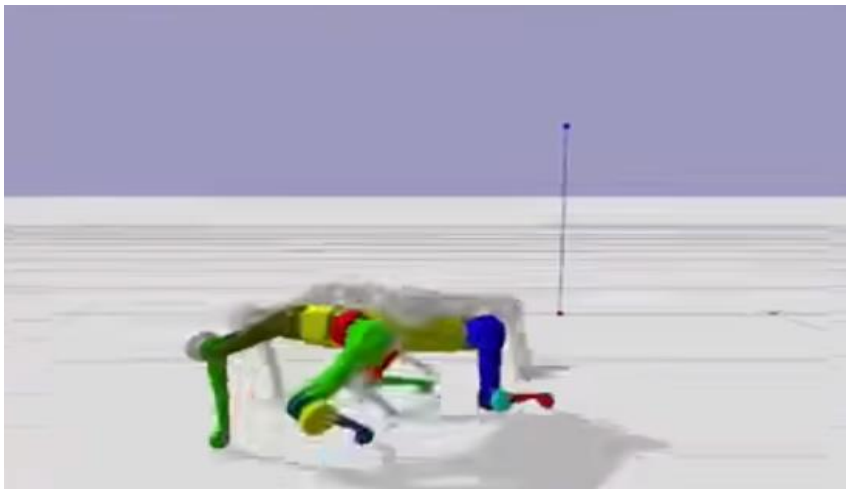
资料来源:腾讯Robotics X,中金公司研究部
随着以深度学习为代表的AI算法的进一步探索,动作捕捉算法有望持续进化。我们认为,近年来以深度学习为基础的动作捕捉算法相比以前已经有了长足的进步,一方面,门槛大幅降低,包括对摄影设备的要求、环境和算力的要求持续降低;另一方面,捕捉精度和画面质量也逐渐提高。近年来,大模型等技术被应用于图像领域,我们预计未来也将引领动作捕捉算法持续积累技术进步,继续朝着将动作捕捉大规模运用的方向努力。
国内布局厂商百家争鸣,AI赋能下应用进入第一梯队
海外动作捕捉技术探索历史较长,微软和英特尔等巨头方案完善,Leap Motion、Xsens后起新秀也较为领先。海外动作捕捉领域,以微软为主的巨头开启了对动作捕捉最早期的探索,尽管受限于时代原因而存在一些不足,但其Kinect是消费级的动作捕捉和体感交互的鼻祖。英特尔则在2014年就推出了体感交互RealSense技术方案,通过深度摄像头实现空间定位和手势交互。此外,Leap Motion等后起之秀也不可忽视。如Leap Motion专注于手指动作捕捉,其能在150度的视场范围内追踪手指,追踪精度达0.01毫米,远超普通的3D运动扫描技术。
动作捕捉领域,目前已有存在大量中国企业积极探索,并得到广泛关注。海外专业媒体BestStartup.Asia在2021年进行相关调研,从中国大量的动作捕捉公司中评选出了“10家中国顶级动作捕捉公司和初创公司”,公司覆盖各种规模,包括初创公司和成熟品牌。结合BestStartup.Asia的调研,国内动作捕捉领域较为领先的企业包括诺亦腾、相芯科技、中科深智、魔珐科技、轻威科技、幻境科技、云舶科技、度量科技、国承万通、瑞立视科技、青瞳视觉等。
诺亦腾在动作捕捉和3D运动测量方面全球领先,解决方案涵盖从开发平台到垂直应用。诺亦腾创立于2012年,在智能感知和交互技术方面全球领先,目前公司已经能够在多个场景下提供全栈解决方案,包括数字媒体、骨科医疗器械、智能医体融合应用等。公司产品及解决方案客户分布广阔,包括全球四十多个国家和地区,电影、游戏、娱乐、医疗手术、运动测评、工业仿真领域均有应用。公司的解决方案早在2015年就参与了美剧《权力的游戏》的制作,剧中万人空巷的壮观场面就来自于诺亦腾的惯性动作捕捉系统,公司参与了大量影视短片的制作。同时,公司和大众汽车、通用汽车、奔驰等车企有VR领域的合作。
相芯科技深耕计算机图形技术与AI技术,提供虚拟人+虚拟物,已收获全球超千家客户。相芯科技创立于2016年,公司发展愿景是成为“元宇宙搭建者”。公司将计算机图形学和AI的相结合,根据公司官网,公司自主研发的“虚拟数字人引擎”和“超写实数字物平台”已经在国内外超千家企业得到了规模化的应用。公司自主研发了人脸跟踪、三维重建、物理仿真、语音合成、AR渲染等技术,并且已在计算机图形学顶级会议ACM SIGGRAPH发表60余篇论文。
中科深智专注XR实时影像技术,在身体动作捕捉和手势动作捕捉领域业内领先。中科深智成立于2016年,核心团队来自于国内著名高校,主要围绕XR实时影像技术。公司在图像合成、动作捕捉、AI动作处理和图像处理等领域申请了70余项专利,在身体捕捉、手势捕捉领域技术领先。业务落地方面,公司聚焦虚拟直播和全栈实时动画领域,发展出虚拟数字人、数字文娱、虚拟现实、高校教育四条解决方案业务线。
魔珐科技全栈自研了智能化工业化虚拟内容制作核心技术、虚拟直播核心技术及AI虚拟人核心技术,并已完成商业化落地。魔珐科技创立于2018年,根据公司官网,魔珐科技目前已完成四轮数亿美元融资,其中C轮融资达到1.1亿美元,公司基于全栈自研的智能化工业化虚拟内容制作核心技术、虚拟直播核心技术及AI虚拟人核心技术构建了三大虚拟世界关键平台化产品线,即三维虚拟内容协同制作智能云平台、虚拟直播和线下实时互动产品、全智能虚拟数字人能力平台,三大平台化产品线已全面落地到文旅、泛娱乐、消费、教育、医疗、电商、通讯、金融等各行各业。
未来畅想:技术行稳致远,应用灿若繁星
技术展望:迈向更高阶的自动化、高精度、低功耗
计算机视觉自上世纪六十年代起源后,每一次性能的提高都伴随着自动化水平的提高:1)深度学习出现前,传统计算机视觉依赖人工识别图像特征,需要工程师手写代码来提取图像特征;2)深度学习的出现帮助人类解决了复杂特征刻画的流程,人类可以使用标注数据训练卷积神经网络,让机器帮助人提取图像的特征,使得计算机视觉的精度取得了一次飞跃。但模型精度严重受到标注数据精度和数据量的制约,标注数据的生产在很多场景下无法实现,在能实现的场景下也会耗费大量人力,这也是当前计算机视觉难以大规模落地的原因;3)通过使用Transformer、DERT等架构,进行无监督的预训练,使得模型具备较为通用的智能,可以大大减少对于标注数据的需求,解决人工标注数据难以获取或成本高的问题。
GPT系列模型以无需人工标记、无监督学习的方式学习视觉“智能”。Image GPT通过采用密集的连接模式,可以在不对二维空间结构进行编码的情况下,实现性能超过采用传统编码的方法。在主流的数据集上,Image GPT在许多指标上超过前人算法的精度,或仅仅是稍逊一筹。Image GPT分为预训练和微调两个部分,其可以通过自回归自动预测图像像素,即使不知道图像的二维结构也可以实现。以下图为例,Image GPT在图像被部分遮挡的情况下仍然能对被遮挡部分给出合理预测。
图表:使用与NLP中GPT-2相同的Transformer架构使得图像生成具备想象力

资料来源:AI公园,中金公司研究部
我们认为,下一步可能是自行生成仿真数据,解决长尾场景数据量少的问题。当前预训练大模型的路线下仍然存在部分极端场景数据量少,难以针对性提高这类场景下模型效果的问题。且视频数据相对于文本数据存在高质量的数据量较少的问题,大模型最终效果受当前数据量的制约。因此我们认为一种可能的方案是通过计算机自行生成仿真数据,使得模型不断自我训练提升效果。
以特斯拉为例,特斯拉自动驾驶通过模拟迭代生成各类极端场景的数据。当前自动驾驶技术落地关键在于解决各类长尾场景,但是各类长尾场景的数据又难以获得,特斯拉自动驾驶团队一方面通过影子模式从终端收集数据,另一方面通过计算机生成仿真数据,包括难以溯源的数据、难以标记的数据、闭塞道路数据等现实世界中案例较少的情况,进一步提高自动驾驶系统应对复杂情况的能力。
图表:特斯拉数据生产从手动标记进阶到自动标记和模拟迭代阶段
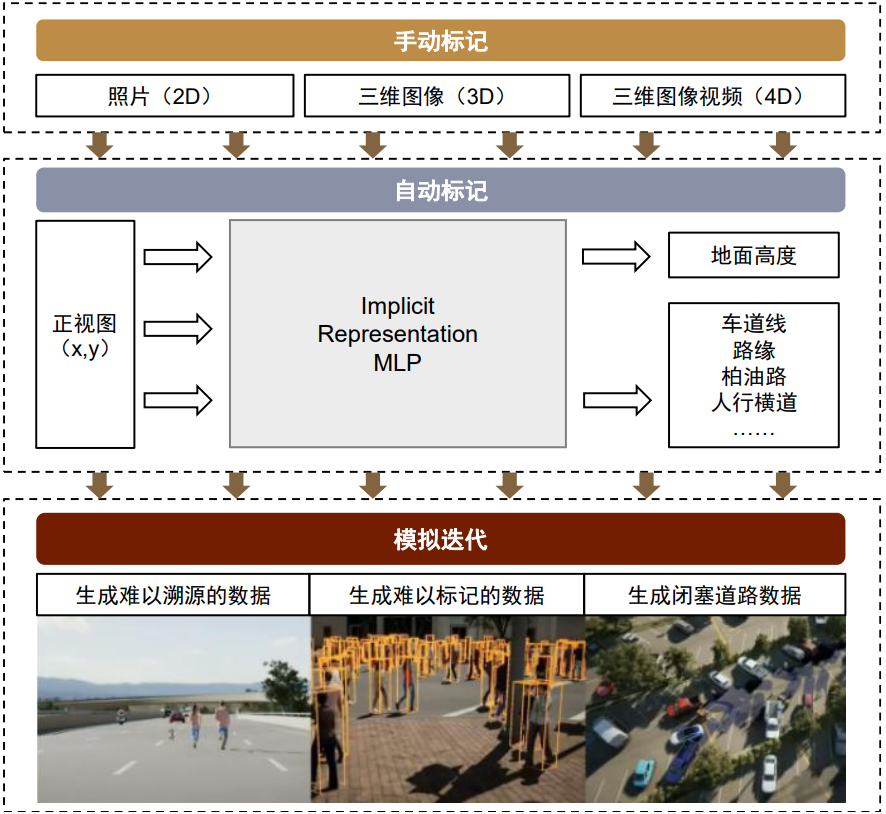
资料来源:特斯拉官网,中金公司研究部
AI助力合成图像数据的技术趋于成熟,仿真效果突出。过去,在Github上有很多合成视频数据的项目尝试,方法包括从统计原理到基于生成式对抗网络(GAN)的原理,但基本都存在效果不够逼真、对使用者编程能力要求较高等问题,但近年来计算机生成图像正在变得越来越逼真。如2021年中科院自动化研究所发布的大规模计算机仿真图像数据集NLPR-LSCGB,其包括超过7万张生成图像,且效果逼真,在颜色、亮度、饱和度等指标上与真实图像接近。
图表:中科院研究院自动化所发布的大规模计算机图像数据集NLPR-LSCGB

资料来源:IEEE Transactions on Image Processing(TIP)期刊,中金公司研究部
应用方向:殊途同源,博采众长
计算机视觉精度的持续提高也带来了越来越多的应用领域。随着近年来,计算机视觉精度持续提高,其也被应用在越来越多的领域上,包括运输、医疗、制造业、基础设施建设、农业、零售业,更多的场景丰富了可用于训练计算机视觉模型的数据,也让人们持续探索将计算机视觉模型全面落地到各类场景的方法。
图表:以计算机视觉为基础的应用领域多点开花

资料来源:V7Labs,IBM,MIT Technology Review,中金公司研究部
动作捕捉、虚拟现实、元宇宙等场景的需求使得计算机视觉越来越多的被应用在三维视觉领域。虚拟现实、元宇宙等场景改变了人与机器之间的交互方式,我们认为这或将影响未来计算机视觉向着三维视觉的方向发展。三维视觉提供比二维视觉更丰富的信息,包括3D成像、自动驾驶、SLAM、三维重建等技术都涉及三维重建的计算机视觉技术。如汽车智能座舱DMS系统需要分析3D人脸信息来判断司机的情绪和精神状态,AR通过三维重建技术完成目标的重现。
动作捕捉领域:为了增加三维重建的训练数据并增强3D建模的精度,我们可以利用深度学习生成3D模型。以MIT的一项研究为例[1],研究者们运用3D生成对抗网络(3D-GAN)网络生成三维模型,使用卷积网络和生成式对抗网络的进展,从概率空间生成三维图像。由于采用了对抗网络,这个生成器能够隐含地捕捉对象特征并生成高品质的3D对象,其可以在无监督的情况下学习,因此可以应用在非常多的领域,包括3D打印、三维重建、自动驾驶和SLAM等技术。
视觉增强领域:使用AI软件进行视觉增强,可以实现精美画面的输出。手机摄影需要借助镜头、感光CMOS、滤光片、ISP图像处理芯片等一系列硬件,但是传统方法在光信号转化成电信号过程中会带来大量损耗和噪声干扰,导致成像质量低。因此使用AI算法进行视觉增强,已经成为常用方式之一。例如手机摄像头中的AI算法,目前市场上很多主流手机都搭载了商汤科技的SenseME水星智能移动终端平台,其提供AI超分辨率的视觉增强。它通过AI算法实现远距离高清摄影,具体原理是通过自动连拍多张照片,将多张照片进行智能融合,完成噪声的降低和照片细节的放大,输出高清图像。AI超分辨率能够在高倍放大后捕捉到各种细节。
当虹科技研发AI老片修复系统,可结合AI和手工修复对影像资料进行快速修复,并通过AI插帧等技术进一步增强画面流畅性,技术已较为成熟。当虹科技为老片修复提供全栈解决方案,其包括媒体数字化处理(将胶片、磁带等媒体转换成数字储存方式),数字媒体修复(对音频、视频进行修复),音视频合成等。当虹科技可以对不同类型老片进行修复,并针对噪点、抖动、闪烁等问题提供针对性解决方案,其通过AI学习海量高清素材并持续迭代技术,对老片图像进行高精度复原,修复效率相对人工修复提升上百倍。此外,当虹科技开发了AI增强技术,可以对修复后视频进行AI插帧,进一步提升老片的画面流畅性。
图表:当虹科技老片修复解决方案核心优势
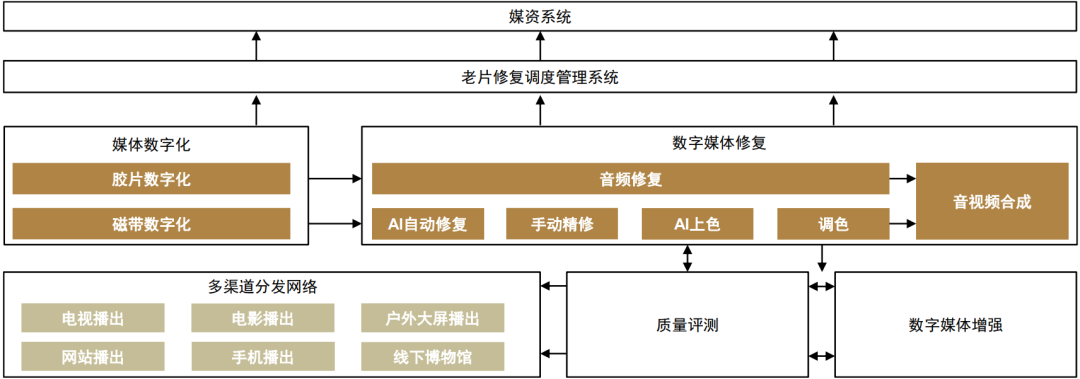
资料来源:当虹科技官网,中金公司研究
医学领域:AI+5G可以帮助去噪、模糊、增强边缘,实现精准的远程手术:1)AI在图像去噪领域可以发挥显著作用,早在2017年,英伟达就在OptiX 5.0框架中引入AI助力的去噪,其通过深度卷积神经网络学习噪声和信号特征的差异,实现区分噪声与信号;2)在AI+5G心脏手术领域,可以使用注意力神经网络对影响自动去噪,使用结果自动建模,从而产生高质量的图像,帮助后续精准的3D建模心脏;3)移动时拍摄时常常导致图片模糊,这类问题可以使用AI大量学习清晰和模糊照片后,自动修复模糊图片。
图表:AI被应用于中国首例AI+5G心脏手术

资料来源:广东卫生信息网站,中金公司研究部
风险提示
深度学习等AI技术进步不及预期。物理世界的“人、物、场”的实时映射和动态交互需要AI技术持续提升来支持。如果以深度学习代表的AI技术不能持续突破,以实现更高程度的自动化、更高的精度、更低的功耗,那么基于视觉的三维重建和动作捕捉技术将很难快速成熟,这可能导致:1)三维重建领域基于视觉的算法图像精度不足、算力需求过大;2)动作捕捉领域基于视觉的动作捕捉方案成本过高、捕捉精度不足。因此,如果以深度学习为主的AI技术不能持续突破,基于视觉的动作捕捉和三维重建技术可能会出现发展停滞的情况。
动作捕捉、三维重建等落地应用进度不及预期。基于计算机视觉的方案在动作捕捉和三维重建领域的应用内尚处于初级阶段,其商业化应用的数量较少、应用领域较为局限。如果相关公司由于落地成本高昂、相关人才稀缺、产品推广效果差等问题导致没有顺利推进先进AI技术的落地,如无法实现高精度、自动化、低功耗的动作捕捉和三维重建产品大规模量产,可能会导致市场关注度低和消费者付费意愿不足,使得技术落地缓慢。
本文选自微信公众号:中金点晴。智通财经编辑:张计伟。


 扫码下载智通APP
扫码下载智通APP