
科技脱碳入硅,美国SaaS企业的智能化进程
本文来自微信公众号“线性资本”(ID:LinearCapital),作者:虞兆恺Kelvin,编辑/翻译:张硕何James。

作者介绍:本文作者虞兆恺Kelvin现就读于普林斯顿大学计算机科学本科二年级,于 2019 年 6 月加入线性资本作为全职暑期实习生。他的邮箱为zkyu@princeton.edu,对此话题感兴趣的读者可以与他联系,感谢来信。本文原题为《SaaS is Evolving: Introducing the New Wave of AI-First Enterprise Solutions 》。
编者按
人是一种由规则组成的碳基生命,进食之于存续,犹如生病之于凋零。
而企业组织是一种由规则组成的群体,在人类进化的长河中,将人所被制定的规则转嫁到了组织之上,直到现在,企业成为了新的群体性生命。
直觉是发自内心的,而理性则是反人性的。
企业的管理如同人的生存之道,这是一个由直觉慢慢总结为经验,再由经验出发提炼出规则的过程。
就像对于猎食动物的恐惧深植在草原部落上原始祖先的海马体中,同样的,对于企业组织的未雨绸缪也是企业领导记忆深处的商业案例的反射。
所以,靠直觉和经验管理企业,是企业大脑中最直接的反射。
一套可被参照且自动执行的智能化流程,是每一个企业最终极的理想。
从最早由经验管理公司,再到S.O.P.的出现,借由网络把S.O.P搬上云端变为SaaS,最后,其实还是期望能进化成可被AI执行的流程。
但是,对于经验的迷信,对于证据的直觉依赖,是存于人类碳基结构的基因之中的。
基于硅体的人工智能不是要复制人的智能,而只是要适应经验的短板。
本文作者纵览发迹于美国硅谷与其他北美地区的SaaS企业,希望能较为全面地展示一套企业组织如何利用A.I.进入到智能化的进程中,勾画一个脱碳入硅的蓝图,为中国SaaS企业提供方法论的参考。
01.作者序
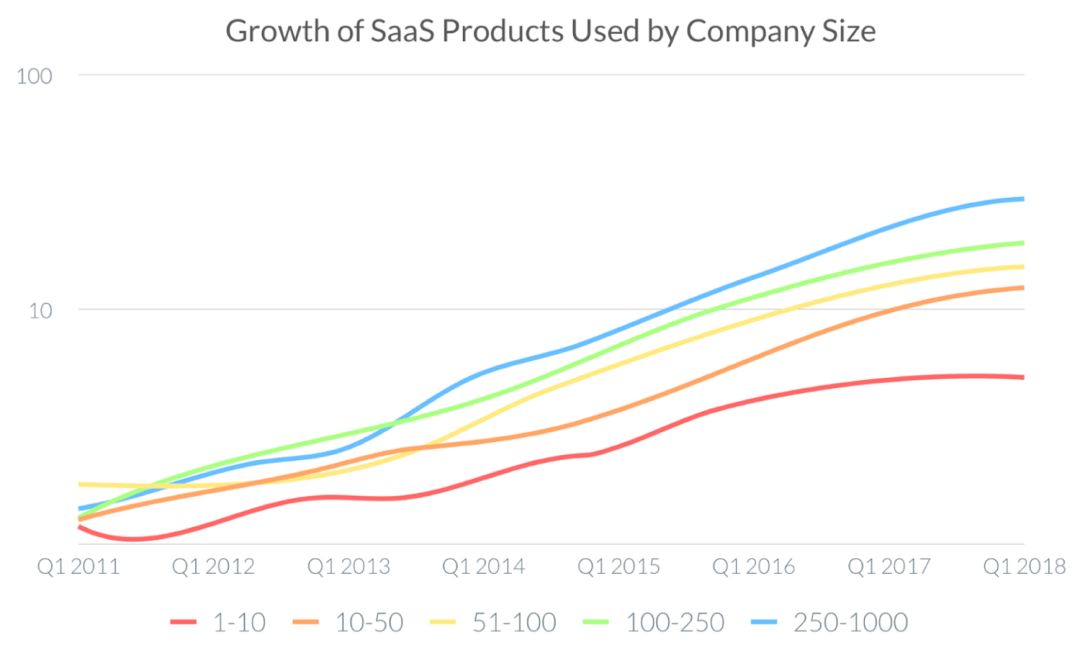
横轴表示为公司规模(以员工数量单位);纵轴表示为SaaS产品的使用量
众所周知,美国的企业们拥有世界上相对来说最深厚的技术储备。
随着各个体量的大小公司纷纷采购SaaS产品,服务于企业端的软件数量激增,也因此造就了一条成熟的软件供给与采购的链条。
以销售科技类公司Chiefmartec为例,在在2011年公司旗下拥有150名销售人员,覆盖了广告、内容管理、客户关系管理、销售、数据分析与公司运营管理等领域。
这一数字在2017年达到了5000名,在如今的2019年更是达到了7040名。
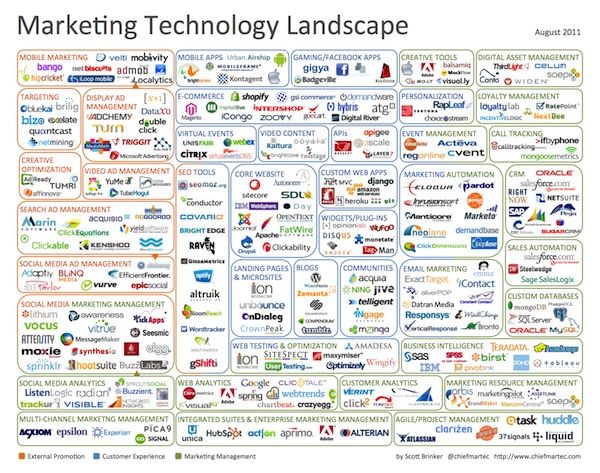
2011年度的销售科技板块:共有150家供货商

2017年度的销售科技板块:共有5000家供货商;到了2019年,数字为7040家供应商
现如今的美国SaaS市场以趋近于饱和,且已经出现了许多平台级的解决方案。
为了用来区分这些产品,我们将传统的SaaS公司归纳为四个不同属性的战略:
1. 用户精准型
区别于传统通用的解决方案,比如Salesforce所提供的,用户精准型的企业擅于在一个绝对垂直领域为其客户细分提供适配且精准的服务,在一定程度上放弃了广阔的市场来达成市场与产品的高度匹配,即「Product-Market-Fit」。
2. 市场细分型
与前者不同的是,市场细分型的企业是从一个市场大小的绝对值来看的,这类企业专注在一个体量比较有限的市场细分下,比如专门服务中小型企业,即「Small and Medium-sized Businesses, SMBs」。
3. 产品精耕型
产品精耕型企业的产品通常强调极大限度地优化产品,可能仅以20%的产品功能便获得了80%的回报,以一个极简化的姿态来参与市场竞争。
4. 双边优化型
双边指的是客户端与企业端,双边优化型的企业擅于在产品战略上让企业端与客户端同时产出价值,让客户成为产品自传播的渠道,从而提升企业价值。
但是,在过去几年中,我们开始看到一种更为独特的企业战略,并且因此孕育了一大批新兴企业。
尽管在这些企业中,他们拥有不同的行业区分和业务区分,但是他们都拥有一个共同的「人工智能先行的战略」,即「AI-First Strategy」。
AI为传统SaaS赋能的过程,可以被看作是一场范式的跃迁。
因为AI赋能之后的软件行业,将呈现出一些从未有过的业务形态、一种千人千面的使用体验、一个未曾想过的商业潜能。
但这也不是说所有的商业模型都适合被AI智能化,企业需要考虑的是从传统架构迁移到智能化平台后所带来的投资回报,一味地追求数字化与智能化,并不会简单地提升所有业务的价值。
因此,本文的核心诉求是给予读者一个价值判断的框架,去理解这个时代变迁后的商业新格局,从新的纬度来看目前格局的企业划分,以及思考一下人工智能为行业和企业带来的结果。
在接下来的章节中,将要为读者展示三种独特的AI结合SaaS战略,正式他们让这些新兴企业与传统SaaS服务提供商区别开来,以及五个来自不同公司的AI应用。
另外,在最后一个章节中,将要讨论为什么SaaS企业的AI赋能却不能带来一个赢者通吃的终局。
值得一提的是,企业AI智能化产业的先驱之一李开复博士是极为看好AI赋能的未来,但是在这里本文根据三个纬度的数据分析,来一一驳斥其中玄机。
02.三种独特的AI+SaaS结合战略
AI+SaaS结合型的企业在功能上也具备之前提到的四种战略的特征,并且在一定程度上,大部分企业可以很轻易使用用户精准型战略的。
但是AI为这些新兴企业赋予了一个全新的产品形态,这点是传统SaaS企业难以望其项背的。
举例来说,随着计算机视觉技术的演进,一个基于面部捕捉和情感分析的商业智能化产业就被开辟出来了。
如今,经销商可以根据客户在购物过程中的体态和表情变化来分析哪一类商品更受欢迎,大学课堂上的演讲和当堂反应也可以被用来分析哪一位老师更能吸引学生注意力。
所以,「AI先行」的公司可以被归纳为三种独特的战略模式:
1. 能借助AI运行超复杂系统和超负荷任务。
以Invenica为例,凭借基于机器学习开发的预测模型能够通过预测多个单点电力栅极的活动状态来管理整个复杂的电力网。凭借此项技术,Invenica更是拿下多个订单,为多个管理系统提供预测模型。
2. 能够借助AI转录和分析以往并不能被数字化的数据形式(e.g. 计算机视觉)。
拿Tractable AI来说,其AI+SaaS的解决方案被应用于汽车保险领域,通过一套成熟的计算机视觉算法,在经过成千上万张受损汽车的图片集训练之后,能够精准快速的分拣车祸保单并移交到相应的流程化处理环节。
3. 能够借助AI将传统SaaS的体验提升10倍以上。
在这里举一个中国公司的例子,助理来也通过搭建智能化的自动应答机器人为企业提供了一个定制化场景的客服应答体验。
「AI先行」的定义可以被诠释为「缺少了AI的赋能,产品所提供的核心价值将一无是处」。
换言之,一个真正的以「AI先行」为核心战略的企业应将AI纳入其价值主张之中。
如果剔除掉AI技术,「AI先行」企业将运行超复杂系统和超负荷任务;同理,缺少了AI,「AI先行」企业将无法理解极为抽象的数据形态,更谈何在其上建构逻辑关系;如果没有了AI,那与传统SaaS企业和企业服务产品有何不同,在已经饱和的市场何来容身之地。
03.三种独特的AI+SaaS结合战略
如前文所述,「AI先行」的SaaS企业与传统SaaS企业在本质上是不同的,接下来我们将探讨一下AI在企业级服务中的实际作用。
尽管AI的功能性划分不尽其数,我们不妨以一种终局的思维分类一下AI多起的作用。传统的功能性划分将AI拆解如下:
首先,智能应用的目的是为了分析商业形式,即「模式识别Pattern Recognition」;其次,便是对未来可能性的预测,即「预测分析Predictive Analytics」;然后,是针对特定限制条件的行为设定以达成结果优化,即「行为优化Optimization」;接着,将这套方法融合进特定的应用场景中,即「场景定制Personalization」;最后,达成在复杂数据之上建立逻辑关联,以此将这套算法推广,即「数据商用Data-as-a-Commodity」。
我们沿着这个逻辑,将公司分别在垂直业务和平行行业两个纬度做更细化的解读:
模式识别
在「模式识别」这个语境中的企业往往擅于从庞大的历史数据中找出隐藏着的关联性,但是这样仅仅是帮助他们理解过去、分析现在,却不能预测未来。
举例来说,Tractable公司从车祸照片的数据中判断出肇事者、损伤程度以及其他的数据样本。
但需要注意的是,Tractable是在利用过去的数据来判断当下所发生的交通事故,并不能对何时何地发生交通事故做出预判。
承上,主要围绕「模式识别」发展业务的公司在自动化决策上是有点薄弱的。
这类公司虽然诟病粗放的人工操作,但是一定不会用机器取而代之。
因为,他们认为人工智能还没有发展足够可靠的地步,而往往项目的沉没成本让公司难以在一个机器程序上试错。
也有公司在尝试跳出「模式识别」固有模式,这里有两个典型的案例:
首当其冲的是CB Insights公司,其业务核心便是利用聚合和分析私有公司底层数据的能力为投资机构提供商业决策。
私有化投资其实和其他品类的投资产品类似,要求挖掘和分析跨行业的、极细颗粒度的行为数据,这原本是人更擅长的抽象工作,而非机器。
第二个例子是利用「模式识别」在早期癌症诊断上的应用。
虽然基于AI技术的癌症诊断工具在许多准确性测试中都优于人类,但是万分之一误诊的可能性都是灾难性的,所以人类常常作为机器诊断的补充,在其后充当着最后一道关卡。

预测分析
应用「预测分析」技术的这类企业很好的诠释了一个问题 - “你从哪里来,要到哪里去?”
其实,这类企业所预测和分析的远远超出了简单地匹配模型并给出可能的预测。
在这个预测的基础上,系统会给出一套可供人做执行的深度建议或直接用机器自动执行任务。
以Zest Finance为例,这家企业利用机器学习帮助借款人可以做更快、更精准的贷款信用的评判。
另一个例子是InsideSales,这家企业通过一个基于人工智能的智能系统为客户做推荐,并实现了15% - 30%的转化。
大多数情况下,预测过程呈现了一个黑箱状态,有一些分析预测型企业往往是将最终决策丢回给人工来操作。
但是,需要指出的是,由机器来做也无非是一个典型的二选一,比如对于Zest Finance来说就是「借」与「不借」的区别。
行为优化
专注于「行为优化」的企业们在解决的问题是 - “如何才能在特定路径上通过优化自身决策来接近企业目标?”
在过去,企业只能依靠一些不尽完美的标的,诸如点击率等来推测一个模糊的用户动向。
但是,自从有了人工智能技术,各项业务都可以在极细分的数据集下来做分析,像是光标路径分析、页面停留时间等等,以此来提升利润空间和留存率等。
举例来说,Nextail和Focal System这两家零售领域的商业智能平台通过分析存货量和跨门店的购买历史,以此给出一个合理的进货数量或是建议周转调配到其他门店。
另一个例子是Amplero,它是一个主要做市场营销的智能平台,所做出的商业分析都是围绕企业的绩效指标来指定的,而非传统的诸如点击率等提升销售、利润空间和留存率等。
表面上看,「行为优化」与「预测分析」类似,两者都是在做面向未来的决策。
但是,不同之处就在于「行为优化」会给出现在可执行的「行为建议」;而「预测分析」,正如其名,是提出可能的「未来走向」。
这就像是一个病人走进医院告诉医生她感到胃疼,这种情况下,「预测分析」算法通常会基于病人的病史以及现在的胃部病症来预测「未来走向」,接下来胃疼程度是会缓解还是更糟.
相较而言,「行为优化」算法会给出一个「行为建议」来指导如何控制疼痛、判断生存预期等等。
甚至,还是在这个例子中,「模式识别」算法也会利用相同的数据来判断病人再次患病的概率。

场景定制
主要做「场景定制」业务的企业会利用人工智能技术营造一种私人订制的体验给终端用户。
还记得第三章第一节所著的Salesforce是如何打败Oracle和SAP的吗?
其胜利的主要原因就是传统大厂即使提供了一系列产品服务,但是很少能匹配云端的需求。
如今又是风水轮流转,当Salesforce身为SaaS大厂在做几乎所有的事情的时候,也不能做到十全十美,因为在各个细分领域都需要做到定制化和功能优化。
根据细分需求是可以让商业决策变得更加精准的,以MailChimp为例,这是一个价值40亿美金的市场营销自动化生意,这家企业为客户提供邮件订阅服务的营销内参,让企业用户们掌握客户画像以及点击数据。
企业用户可以轻易掌握到这些数据,了解其客户的所做所想,但是没有「场景定制」的弊端就在于,这家企业的邮件订阅内容在同一时段给不客户提供的是同样的内容。
客户根据各自的需求去挑选合适的产品,但是大部分的SaaS营销工具并不能提供场景定制化的功能。
但是有一家目前走过B轮的中国创业公司能提供不一样的角度,那就是由人工智能驱动的数字内容平台特赞,它为企业客户提供了千人千面的网页头版和横幅等的设计。
在一份埃森哲于2018年发布的调查中,来自欧洲和北美的8000名受访者中有接近91%的人认为基于个人需求定制的广告和推荐是更受欢迎的,另有74%的人愿意提供个人数据以供运营商为他们推送定制化内容。
对于直接那些需要与客户直接打交道的SaaS产品来说,诸如CRM平台、市场营销平台还有聊天机器人应用等等,拥有定制化的功能和内容将为公司在早期建立起一定的竞争壁垒。
但是随着人工智能商业化的普及,定制化需求正在成为必要的前提,提供定制化的服务一定是未来「AI+SaaS」的发展方向。

数据商用
当数据收集的需求和对人工智能技术的依赖在不断增加时,便会产生平台效应,一些高阶的技术工具聚集在平台之上可供各个量级的用户调取,这就像是用户在使用亚马逊云服务平台一样方便。
谷歌便是利用其自身的人工智能和机器学习的技术储备在向这样一个开放的数据平台发展,但是与其同时,这一领域已经汇集不少玩家。
比如说,有提供计算机视觉引擎API的Clarifai公司、提供人工数据整合服务的MostlyAI公司、为企业客户提供原始销售数据的Tonic公司等。
这些公司甚至不必成为一家真正的、以「AI」为核心的公司,因为在他们所处的各自领域都在享受到有人工智能增值带来的二阶效应。
以Segment和Snowflake为例,这两家公司都推出了企业客户系统化管理数据的服务,但是他们都不是典型的有人工智能技术起家的公司,而且他们现在分别估值15亿美元和39亿美元。
「数据商用」型企业和此前提到的「场景定制」型企业类似,都是为典型的垂直领域用户服务,因为他们真正在售卖的是一种企业后台工具。
不过数据/AI商用型公司与只服务于垂直场景的AI定制化公司的规模似乎比较能看到天花板,当这个细分场景的掘金潮来临时,似乎是一门好生意。
Domino Data Lab的发迹历史就是很好的证明,他们向数据科学家出售软件解决方案,以此帮助他们的客户进行模型的快速搭建和配置。
自然地,他们也获得了来自风险投资机构的超过8000万美元的融资。

04.为什么AI技术不会导向赢者通吃的市场终局
此前,我们已经基本遍历了AI在SaaS企业中的应用前景。
而至于AI在SaaS企业中的应用弊端,这就说来话长了。
不过,似乎有一种声音正在出现,即是通过应用AI技术可以让企业走向一个相对垄断的市场地位。
因为AI行业的入门门槛是相对高的,只有资源顶端的公司可以为如此高成本的人力买单。
与此同时,AI的产业链条中,数据收集、将数据喂给AI模型、打造AI产品、收集更多数据来正向反馈给这个链条,可以看出这是一个赢者愈赢、强者愈强的局面。
表面上看,这是符合逻辑的,因为模型是依赖于更精确的数据源,只要是能获取到精准的数据,那么占据在这个身位上就一定能比后来者更有先手优势。
而所训练出来的模型,反过来会让先发企业创造更好的产品,这样一来就拥有更多的资源去投入到获取数据中。
知名的技术领域风险投资人、AI领域的研究专家李开复博士曾经在其著作《AI·未来》中有总结到:
AI在某些行业内是一定会取得赢者通吃的局面。深度学习与数据挖掘的关系造就了一个闭环,并且在不断地为优秀的公司和产品赋能。 因为更充足的数据会造就更优秀的产品,这也会吸引更多的用户,而用户会产生更多的数据为产品迭代产生动力。 这些数据池和其带来的巨大利润会为头部的公司们吸引来头部的开发人员,这样一来,公司与公司之间的差距就愈发明显。
其实,争议主要围绕三个最基本的假设:
1. 头部玩家可以在很长的一段时间持续获取到有效数据。
2. 更多的数据和更好的模型之间存在线性正相关的关联。
3. 未来AI方面的人才仍然处于一个供应短缺的高价状态。
显然,这些假设并不能成立,而以下是三个驳斥点:
1. AI技术和数据的商用化正在崛起。
2. 数据和数据产生的价值正逐渐成负相关。
3. AI技术从业者的入门门槛正在降低。
05.AI技术和数据的商用化正在崛起
当数据收集的需求和对人工智能技术的依赖在不断增加时,便会产生平台效应,一些高阶的技术工具聚集在平台之上可供各个量级的用户调取,这就像是用户在使用亚马逊云服务平台一样方便。
谷歌便是利用其自身的人工智能和机器学习的技术储备在向这样一个开放的数据平台发展,但是与其同时,这一领域已经汇集不少玩家。
比如说,有提供计算机视觉引擎API的Clarifai公司、提供人工数据整合服务的MostlyAI公司、为企业客户提供原始销售数据的Tonic公司等。
这些公司甚至不必成为一家真正的、以「AI」为核心的公司,因为在他们所处的各自领域都在享受到有人工智能增值带来的二阶效应。
以Segment和Snowflake为例,这两家公司都推出了企业客户系统化管理数据的服务,但是他们都不是典型的有人工智能技术起家的公司,而且他们现在分别估值15亿美元和39亿美元。
开复老师认为的头部公司所具有的显著优势是持续获得有效数据的能力,但是在未来这一点很可能不复存在。
真实的数据生产过程是为了能测试和改进AI模型的人工数据生产过程。
一个实现的基本路径是记录真实世界的数据是如何分布的,之后根据分布结果来做统计。
问题的复杂之处在于这个过程需要足够先进的收集方法,但是正如读者所见,在文章开头的板块图中,已经有创业公司在尝试「数据创造即服务,Data-Generation-as-a-Service」。
此项技术已经被Waymo和Tesla应用在自动驾驶的模拟中。
在2019年7月,Waymo已经完成了1千万英里的模拟驾驶,但于此同时,真人驾驶的数据累计也才1千万英里,此处可以看到模拟数据在执行时的效率。
总结来说,获取、管理、应用数据正日益变得渐变,当真实数据的生产方式让相关数据变得更容易获取时,独角兽企业Segmet和Snowflake证明了数据管理可以更简化10倍,Clarifai和Google将AI集成到栈也可以更简化10倍。
06.数据和数据产生的价值正逐渐成负相关
风险投资基金Andreessen Horowitz的投资人Martin Casado和Peter Lauten曾经对于数据领域的护城河效应有一个著名的论调:
诚然,这个行业是有规模效应的,但是我们观察到数据领域的护城河并不稳固。 因为和传统行业的规模化不同,传统行业往往越早吸引到投资,相对优势就越发明显。而数据领域其实有些背道而驰,获取特异性的数据资源让成本陡升,但是数据所累计的价值缺越来越不明显。
有一种论调是说数据的门槛是当收集了更多的数据之后能正向促进模型的精准度。
在某些语境下这是对的,比如当AI可以很显著地达成网络效应的地方(e.g. Tiktok)。
但是更多的时候,数据收集和清洗带来的成本往往高居不下或持续增加,而新数据的多样性却不能被保证。
最终数据采集的价值曲线持续放缓,甚至会有所回落。
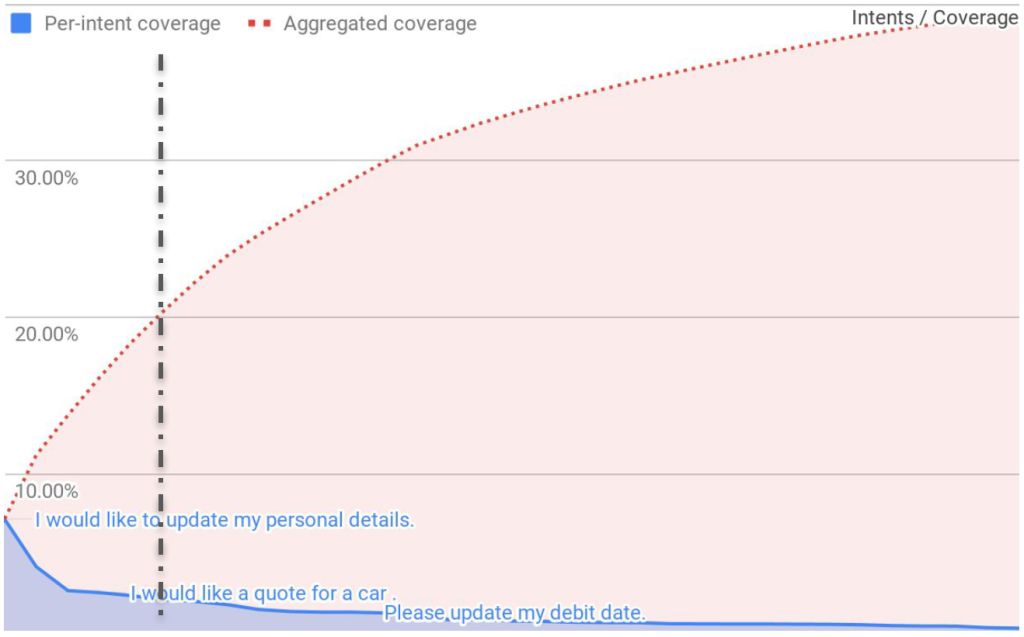
以上图表来自于Eloquent Labs的Aru Chaganty,显示了客户支持领域内提交给智能问答机器人的一些提问。
a16z基金还表示:
在这其中,在20%的系统资源临界点,系统一共处理了20%的客户请求。 在这个临界点之上,数据处理的效率曲线不但明显增长缓慢,处理成本也随着数据抓去和清洗量上升而陡增。 另外一个值得注意的点是,数据分布的极限是往40%这个点无限趋近,这就意味着自动应答可被执行的内容范围的极限就是这个量
如果读者熟悉机器学习的话,还可以从另一个角度来思考这个问题,那就是「主成分分析 Principal Component Analysis」,即「PCA」。
「PCA」是一种数据降维算法,将n维特征映射到k维上,这k维是全新的正交特征也被称为主成分,是在原有n维特征的基础上重新构造出来的k维特征。
事实上,在噪音较大的数据集中,在前几个纬度内捕捉到了大部分信号内容,而之后的纬度充满了噪音。
同样的,数据收集在达到某一个临界点之后,再增加的新数据边际效应就很有限了。
换言之,数据收集呈现了一种明显的幂次法则,或者说帕累托分布:在某一个临界点之下,数据对于达成更精准的模型是很重要的,但是当数据的采集量逐渐逼急10倍或100倍时,对于模型精准度的贡献在成本和功能上都十分有限。
AI对于有些终端是管用的,比如最终目的是提升用户体验和用户价值的,而不是模型本身。
至此,再回过头来看一下「AI赢者通吃论」的前两个假设条件。
第一,头部玩家可以在很长的一段时间持续获取到有效数据;第二,更多的数据和更好的模型之间存在线性正相关的关联。本文所秉承的观点就是「AI/数据商用化」企业会有效降低行业的入门门槛,因此第一个假设不攻自破。
第二点,也是更重要的一点,即更多的数据并不一定会造就更精确的模型。
07.AI技术从业者的入门门槛正在降低
如果「AI/数据的商用化」正在从技术层面上让AI模型的搭建变得简易,但是为什么这拉低AI从业者的入门门槛呢?
接下来需要用软件工程来做一下类比。
比方说,读者想要学习如何在iPhone上搭建一个移动端应用,在早期会怎么做呢?
很大可能是买来一本厚重的编程书,或是雇佣一个助教,又或者是在网上钻研晦涩难懂的文章。
在过去的十年中,这一局面获得了很大的改观。
如今,根本用不上翻阅难啃的开发教程或是上昂贵的编程课,在网络上已经拥有了庞大的、已用的公开教学资源,而且大部分还是免费的。
比如,在StackOverflow上,无需依靠阅读文档来艰难地找出Bug,论坛里的帖子能回答几乎所有新手会犯的错误。
但是不仅如此,AWS和Heroku提供的SaaS、PaaS和IaaS的解决方案能够显著地带来简单易用的机会去视觉化、检测、运维和发布任何客户端应用产品。
读者也许会反驳到,这个论述只看到了产业中下游的提升,在上游的精英级别从业者们并不会因此改变太多。
在此,本文的立场应该是与这种反驳完全对立的。
当一个行业的信息壁垒降低,有机会让足够多的人持续进入这个行业时,处于顶层的精英人数一定有机会同比增加。
不过,在这里还是引用一下行业专家李开复自己的话。
他的这段文字阐述了他认为的为什么科技人才可能造就AI领域成为领头行业的原因:
顶尖的公司把充足的数据量与资本结合起来,就能吸引到顶尖的人工智能人才,进一步扩大产业领先者与落后者之间的差距。
同意。我们继续来看他在书中是如何比较研究领域和应用领域的:
许多人之所以误认为美国在人工智能领域具有重大优势,主要是因为他们还停留在我们生活在「发明的年代」的印象中: 在发明的年代,人工智能的顶尖研究人员不断打破旧有典范,最终破解存在已久的谜题,媒体不断报道人工智能的最新成就,更是助长了这种印象。 例如在某些癌症的诊断上,人工智能做得比医生更好;在德州扑克的人机大赛中,人工智能击败了人类冠军;不用人为干预,人工智能就自己学会并精通新技能等。 媒体如此关注报道人工智能的每一项新成就,也难怪一般观察者甚至是专业分析师会认为人工智能研究将不断获得突破性的新发现。
他认为,这种现象有误导作用,因为在这些「新里程碑」中,很多成就其实只是把过去10年的技术性突破应用到 新问题上。
其中主要是深度学习,但还有一些互补的技术,例如强化学习(reinforcement learning)和迁移学习(transfer learning)。 研究人员做这些事,需要卓越的技能和深度的专业知识,不仅要有能力思考、撰写复杂的数学算法,还要能够处理巨量数据,针对不同问题调整人工神经网络。 这往往需要博士级的专业知识技能,但这些发展都不过是依赖着深度学习这项科技的大发展所做的渐进式改善和优化。 这些渐进式的改善和优化,其实是把深度学习在模式识别与预测上的强大能力应用到种种不同的领域上,如疾病诊断、核发保单、开车、中英翻译等。
这其中理由也很简单:
但这些改善和优化并不代表我们正在朝着「通用人工智能」的方向快速前进,或是出现了类似深度学习的重大技术性突破。简单来说,人工智能正式进入了实干的年代,想要利用这个时期赚钱的公司,需要拥有有远见和才干的创业者、工程师和产品经理。
他还补充到:
想要训练处成功的深度学习算法,需要运算力、工程能力以及大量的数据。在未来这三点中最重要的是数据量,因为工程能力达到一定水平后,就会开始出现收益递减,这时数据量才能决定一切。只要数据量足够大,由优良但非顶尖的工程师设计出的深度学习算法,也有机会超过全球顶尖专家设计的算法。
行业精英们肯定可以帮助头部企业巩固住他们的地位。
但是,我们是处于一个增量的时代,是不是普通工程师也能完成实操,因为毕竟数据为王?
答案是否定的,不,这并不能说得通。
持续吸引优秀的人才和保持人才的运转是创造任何壁垒的必要条件,但是开复博士自己也坦言,这在AI并不是至关重要的。
虽然AI的核心人才还是相对稀缺的,但是需要指出的是,行业的入门门槛正在降低。
此外,市场的流动性给越来越多的从业者提供了机会,类似于1997年和2014年计算机从业者数量翻番。
中国发布了将要在2030年引领全球AI市场的国家战略,因此2019年已有超过400所高校开展并设立了AI、大数据、机器人相关的专项教育。
这样的宏观刺激会显著提升AI从业者的基数,而且技术工具的使用壁垒也在下降,所以AI从业者的总体数量会比预计乐观很多。
08.总结
来到最后,回到本文所给出的三个最终结论:
AI技术和数据收集管理正在被大幅度简化和商用化;
数据和数据产生的价值正逐渐成负相关;
AI技术从业者的入门门槛和使用工具的学习壁垒正在降低,人才供应会逐步提升且成本会降低。
我们可以得出一个结论,AI技术并不能确保运用它的企业走向赢者同者通吃的局面。在一个行业中的绝对优势是建立在能够同时在多个纬度处于领先:人才储备、数据广度、数据深度、产品体验还有资本储备。
无数的例子证明,曾经的领先者会因为相同的原因而落没。
首先,他们获得资金;然后,安于舒适区;最后,他们死去。
AI是某些终端的解决办法之一,但是不要让这个技术本身蒙蔽了企业未来的发展道路。保持多条路径并行,持续饥渴、不断迭代,去寻找未来新的增长点。


 扫码下载智通APP
扫码下载智通APP